This is a post of a series on our approaches.
Environment Variables
The environment variables offer a good solution to define external changes.
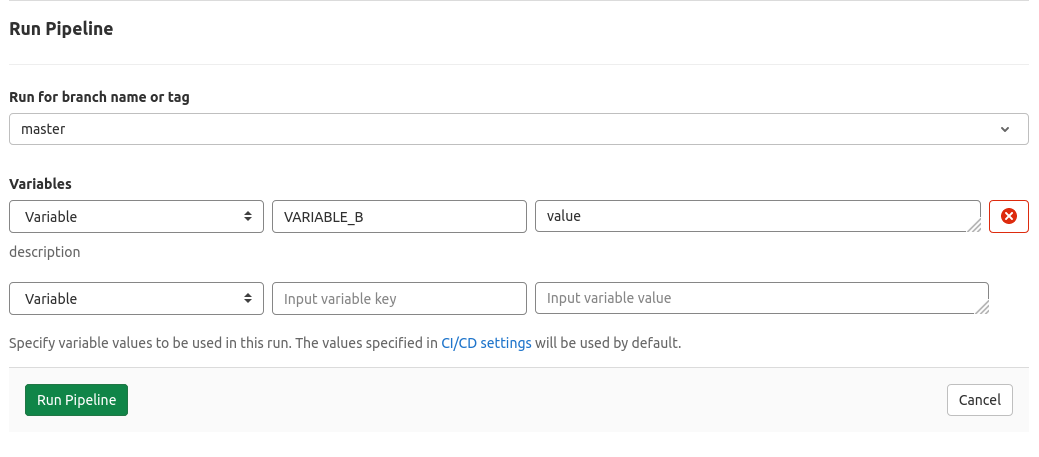
There are two was to define them, both use the same variables directive, but one allows us to define a description which will be shown in the UI when manually triggering the pipeline.
variables:
# without description
VARIABLE_A: "value"
# with a description
VARIABLE_B:
value: "value"
description: "description"
Using Environment Variables
Environment variables can be called by their name in a bash like manner - $VARIABLE_NAME.
We will be using our tools.gitlab-ci.yml and our .gitlab-ci.yml from our first blog post for this examples.
# tools.gitlab-ci.yml
job:
stage: build
image: alpine:latest
before_script:
- echo "some tool specific setup"
script:
- echo "default action"
# .gitlab-ci.yml
include:
- local: tools.gitlab-ci.yml
For the beginning we want to just replace our echo with a variable, let’s call it ECHO.
# tools.gitlab-ci.yml
job:
stage: build
image: alpine:latest
before_script:
- echo "some tool specific setup"
script:
- echo "$ECHO"
Defining Environment variables
There are multiple ways how we can define the environment variables, each of them has their pros and cons. I will try to shed some light and also reveal some of the thought processes behind it.
within .gitlab-ci.yml
I would not recommend to go this way, as the user needs to have deeper knowledge of the jobs.gitlab-ci.yml.
At least not fully, in later examples i will show you, how you can leverage this functionality together with the jobs.gitlab-ci.yml
Defining it within .gitlab-ci.yml can be achieved in two ways.
Either we define it globally like
# .gitlab-ci.yml
variables:
ECHO: "our echo"
include:
- local: tools.gitlab-ci.yml
… or we define it on the job like
# .gitlab-ci.yml
include:
- local: tools.gitlab-ci.yml
job:
variables:
ECHO: "our echo"
within tools.gitlab-ci.yml
When you extracted functionality into an own .gitlab-ci.yml-file, i recommend to provide either a good documentation about the options or make the extracted file as self explanatory as possible.
A simple way to achieve this, is using the value and description definition for environment variables.
This might spoil the overview of your pipeline, but there are ways to bypass this, which i will show you later.
Defining it is similar to the .gitlab-ci.yml file:
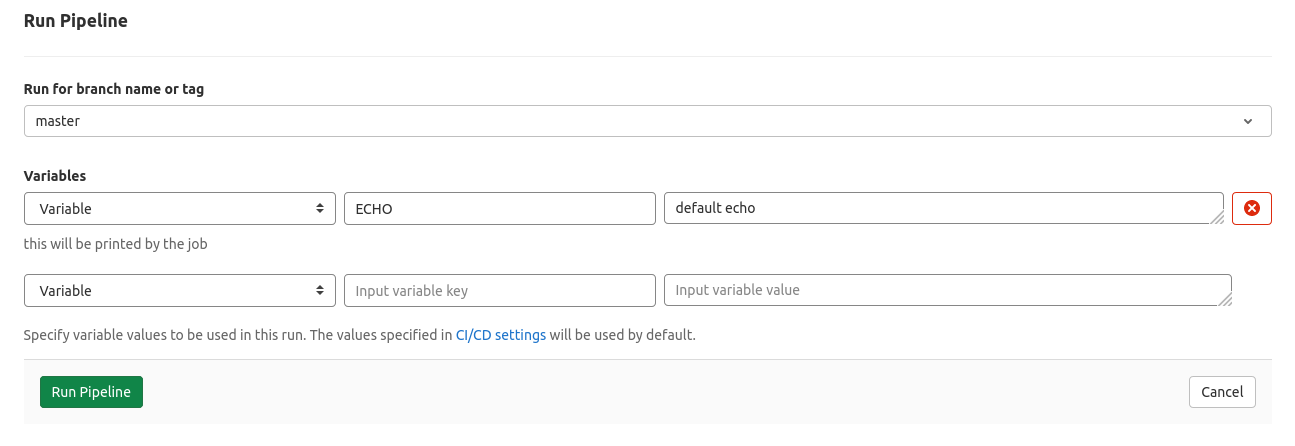
# tools.gitlab-ci.yml
variables:
ECHO:
value: "default echo"
description: "this will be printed by the job"
job:
stage: build
image: alpine:latest
before_script:
- echo "some tool specific setup"
script:
- echo "$ECHO"
Overwriting
You also maybe want to overwrite those variables. There are a few ways we can overwrite it:
- Copy/Paste/Replace
- Overwrite and Hide
Copy/Paste/Replace
Therefore we can even combine the two ways of defining them within the .gitlab-ci.yml, and provide a better readable and described variable for our run dialog.
# .gitlab-ci.yml
variables:
ECHO:
value: "our echo"
description: "this will be printed by the job now as we overwrite it"
include:
- local: tools.gitlab-ci.yml
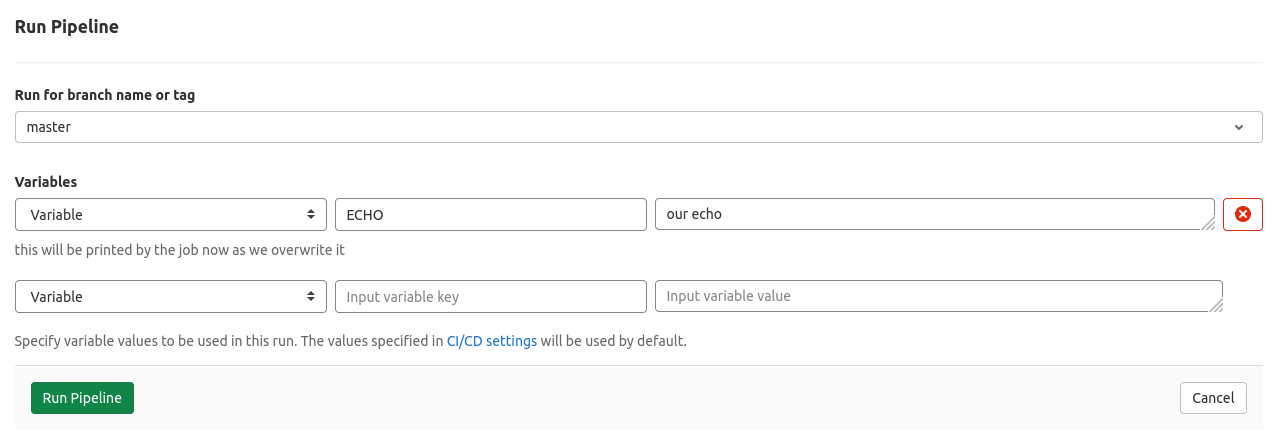
This will still show this information on the run pipeline-form.
Overwrite and Hide
The first approach showed us, how we can copy, paste and replace this information. Maybe we want to not “spoil” our form, as we do not need to manipulate it anyways.
If not we are provided with simple tools and replace the definition with the first version.
# .gitlab-ci.yml
variables:
ECHO: "our echo"
include:
- local: tools.gitlab-ci.yml
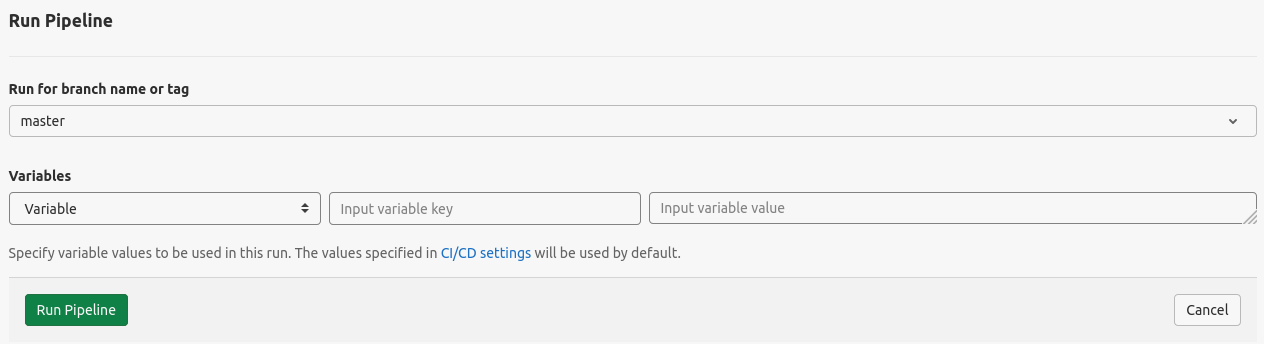
Hiding extracted environment variables
Sometimes we are fine with the default values and do not want to show any information about this variable within the run pipeline-form.
For smaller includes this can be easy, as the number of environment variables is small.
# .gitlab-ci.yml
variables:
ECHO:
description: ""
include:
- local: tools.gitlab-ci.yml
But it again forces the user to have prior knowledge of his include, or if the include changes to also maintain his own build.
with an own file
As we were facing this regularly we came up with a small hack. For each of our includes, we provide a second include, with the sole purpose of hiding the variables. Besides the effect of hiding the variables, we are also able to provide additional information of the basic include to the user.
You might be wondering how we name this file and what the content is.
We named it tools.hide.gitlab-ci.yml and it just copies the environment variables of tools.gitlab-ci.yml but replaces the description.
# tools.hide.gitlab-ci.yml
variables:
ECHO:
description: ""
The include within the .gitlab-ci.yml file is working the same way.
Now somebody can actively turn the description on and off if needed.
# .gitlab-ci.yml
include:
- local:
- tools.gitlab-ci.yml
- tools.hide.gitlab-ci.yml
Conclusion
It is easy to provide some kind of configuration to the user. It is also fairly easy to document them and make it visible within the pipeline. Also with our hack it is easy to hide them, if they are not needed.
Word of Advice
Those are highly opinionated solutions, which are covering our use cases. They might not be the ideal fit for your solution. But I hope they offer inspiration.
]]>